来源:倍可亲(backchina.com)
2016年3月12日人机大战第三局,AlphaGo执白176手中盘胜李世石,以3:0的比分提前取得了对人类的胜利。
这一局李世石败得最惨,早早就被AlphaGo妙手击溃,整盘毫无机会。最后李世石悲壮地造劫,在AlphaGo脱先之后终于造出了紧劫。但AlphaGo只靠本身劫就赢得了劫争,粉碎了AlphaGo不会打劫的猜想。这一局AlphaGo表现出的水平是三局中最高的,几乎没有一手棋能被人置疑的,全是好招。三局过去,AlphaGo到底实力高到什么程度,人们反而更不清楚了。
看完这三局,棋界终于差不多绝望了,原以为5:0的,都倒向0:5了。有些职业棋手在盘算让先、让二子是否顶得住。整个历程可以和科幻小说《三体》中的黑暗战役类比,人类开始对战胜三体人信心满满,一心想旁观5:0的大胜。一场战斗下来人类舰队全灭,全体陷入了0:5的悲观失望情绪中。
我也是纠结了一阵子,看着人类在围棋上被机器碾压的心情确实不好。但是承认机器的优势后,迅速完成了心理建设,又开心地看待围棋了。其实挺容易的,国际象棋界早就有这样的事了。这个可以等五盘棋过后写。
现在我的感觉是,棋界整体还是对AlphaGo的算法以及风格很不适应。一开始轻视,一输再输,姿态越来越低,三盘过后已经降到一个很低迷沉郁的心理状态了。这也可以理解,我一个围棋迷都抑郁了一会,何况是视棋如生命的职业棋手。但是不管如何,还是应该从技术的角度平心静气地搞清楚,AlphaGo到底是怎么下棋的,优势到底在哪些,是不是就没有一点弱点了?
现在有了三盘高水平的棋谱,质量远高于之前和樊麾的五盘棋谱。还有谷歌2016年1月28号发表在《自然》上的论文,介绍了很多技术细节,还有一些流传的消息,其实相关的信息并不少,可以作出一些技术分析了。
之前一篇文章提到,从研发的角度看,谷歌团队把15-20个专家凑在了一起,又提供了巨量的高性能计算资源,建立起了整个AlphaGo算法研究的“流水线”。这样谷歌团队就从改程序代码的麻烦工作中解放出来,变成指挥机器干活,开动流水线不断学习进步,改善策略网络价值网络的系数。而且这个研发架构似乎没有什么严重的瓶颈,可以持续不断地自我提升,有小瓶颈也可以想办法再改训练方法。就算它终于遇到了瓶颈,可能水平也远远超过人类了。
这些复杂而不断变动的神经网络系数是AlphaGo的独门绝技,要训练这些网络,需要比分布式版本对局时1200多个CPU多得多的计算资源。AlphaGo算法里还是有一些模块代码是需要人去写的,这些代码可不是机器训练出来的,再怎么训练也改不了,谷歌团队还不可能做到这么厉害。例如蒙特卡洛搜索(MCTS)整个框架的代码,例如快速走子网络的代码。这里其实有两位论文共同第一作者David Silver和Aja Huang多年积累的贡献。这些人写的代码,就会有内在的缺陷,不太可能是完美无缺的。这些缺陷不是“流水线”不眠不休疯狂训练能解决的,是AlphaGo真正的内在缺陷,是深度学习、self-play、进化、强化学习这些高级名词解决不了的。谷歌再能堆硬件,也解决不了,还得人去改代码。
第一局开局前,谷歌就说其实还在忙着换版本,最新版本不稳定,所以就用上一个固定版本了。这种开发工作,有可能就是人工改代码消除bug的,可能测试没完,不敢用。
总之,像AlphaGo这么大一个软件,从算法角度看存在bug是非常可能的。在行棋时表现出来就是,它突然下出一些不好的招数,而且不是因为策略网络价值网络水平不够高,而是MCTS框架相关的搜索代码运行的结果。如果要找AlphaGo潜在的bug,需要去仔细研究它的“搜索 ”。这可能是它唯一的命门所在,而且不好改进。
那么MCTS的好处坏处到底是什么?幸运的是,Zen和CrazyStone等上一代程序,以及facebook田渊栋博士开发的Darkforest都用了MCTS。它们和AlphaGo虽然棋力相差很远,但是行棋思想其实很相似,相通之处远比我们想象的高得多。

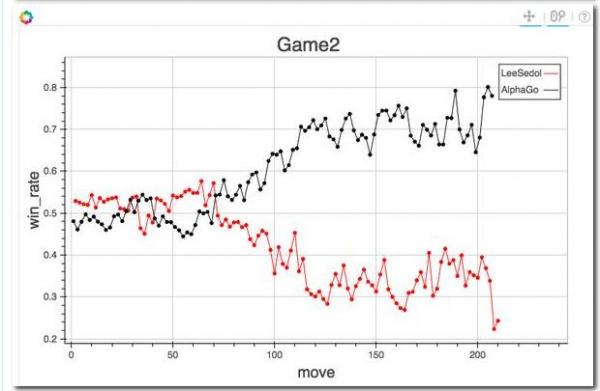
这是田渊栋贴的Darkforest对前两局的局势评分。可以看出,这个评分和棋局走向高度一致,完全说得通。而且谷歌也透露了AlphaGo对局势的评分,虽然一直领先,但第二局也有接近的时候,能够相互印证。如果到网上下载一个Zen,输入AlphaGo和李世石的对局,选择一个局面进行分析,也会有像模像样的评分出来。这究竟是怎么回事?
从技术上来说,所谓的局势评分,就是程序的MCTS模块,对模拟的合理局面的胜率估计。连AlphaGo也是这样做的,所以几个程序才能对同样一个局面聊到一块去。所有程序的MCTS,都是从当前局面,选择一些分支节点搜索,一直分支下去到某层的“叶子”节点,比如深入20步。
这个分支策略,AlphaGo和Darkforest用的是“策略网络”提供的选点,选概率大的先试,又鼓励没试过的走走。到了叶子节点后,就改用一个“快速走子策略”一直下完,不分支了,你一步我一步往下推进,比如再下200步下完数子定出胜负。这个走子策略必须是快速的,谷歌论文中说AlphaGo的快速走子策略比策略网络快1000倍。如果用策略网络来走子,那就没有时间下完了,和李世石对局时的2小时会远远不够用。下完以后,将结果一路返回,作一些标记。最后统计所有合理的最终局面,看双方胜利的各占多少,就有一个胜率报出来,作为局势的评分。一般到80%这类的胜率就没意义了,必胜了,机器看自己低于20%就中盘认输了。
AlphaGo的创新是有价值网络,评估叶子节点时不是只看下完的结果,而是一半一半,也考虑价值网络直接对叶子节点预测的胜负结果。走子选择就简单了,选获胜概率最大的那个分支。机器也会随机下,因为有时几个分支胜率一样。
MCTS这个框架对棋力最大的意义,我认为就是“大局观”好。无论局部如何激烈战斗,所有的模拟都永远下完,全盘算子的个数。这样对于自己有多少占地盘的潜力,就比毛估估要清楚多了。以前的程序,就不下到终局,用一些棋块形状幅射之类的来算自己影响的地盘,估得很差,因为一些棋块死没死都不清楚。MCTS就不错,下到终局死没死一清二楚。MCTS也不会只盯着局部得失,而是整个盘面都去划清楚边界。这个特点让几个AI对局势的评估经常很相似,大局观都不错。MCTS对于双方交界的地方,以及虚虚实实的阵势,通过打入之类的模拟,大致有个评估。当然这不是棋力的关键,大局观再好,局部被对手杀死也没有用,可能几手下来,局势评估就发生了突变。
AlphaGo的大局观还特别好,特别准确,主要是它模拟的次数最多,模拟的质量最好。而且这个大局观从原理上就超过了人类!比如人看到一块阵势,如果不是基本封闭的实空,到底价值多少评估起来其实是非常粗的。高手点目时经常这样,先把能点的目算清楚,有一些小阵势如无忧角就给个经验目数,然后加上贴目算双方精确目数的差值,然后说某方的某片阵势能不能补回这个差值,需要扣除对方打入成的目数,孤棋薄棋减目数。这类估算有很多不精确的因素。
AlphaGo就不一样了,它会真的打入到阵势里,来回模拟个几十万次,每一次都是精确的!人绝对没有能力像AlphaGo这么想问题,一定是利用经验去估算阵势的价值,误差就可能很大。极端情况下,一块空有没有棋,职业棋手根本判断不清,AlphaGo却可以通过实践模拟清楚,没棋和有棋相比,目数差别太大了。AlphaGo虽然不是严格证明,但通过概率性地多次打入模拟,能够接近理论情况,比人类凭经验要强太多了。我可以肯定,AlphaGo的大局观会远远超过职业高手,算目也要准得多,所以布局好、中后盘收束也很强大。甚至Zen之类的程序大局观都可能超过职业高手。
例如第二局这个局面:

李世石左下占了便宜,本来局势还可以。但是他70和72手吃了一子落了后手,被AlphaGo走到73,大局一下就落后了。这个在前面Darkforest对局势的评估图中都非常清楚,是局势的转折点。李世石要是手头有个Zen辅助,试着下两下都可能会知道70手不要去吃一子了。大局观不太好的职业高手,比如李世石就是个典型,大局观不如Zen真不一定是笑话。李世石比Zen强的是接触战全局战的手段,要强太多了。MCTS实事求是不怕麻烦下完再算子的风格,比起人类棋手对于阵势价值的粗放估算,是思维上先天的优势。
AlphaGo比其它程序强,甚至比职业高手还强的,是近身搏杀时的小手段。

第三局,李世石29和31是失着。29凑白30双,虽然获得了H17的先手,但是中间的头更为重要。当黑31手飞出后,白32象步飞可以说直接将黑击毙了。在盘面的左上中间焦点处,AlphaGo的快速走子网络会有一个7*7之类的小窗口,对这里进行穷举一样的搜索,用人手写的代码加上策略网络。32这步妙招可能就是这样找出来的,李世石肯定没有算到。但是AlphaGo是不怕麻烦的,就一直对着这里算,比人更容易看到黑三子的可怜结局。这个计算对人有些复杂,只有实力很强的才能想到算清楚,对AlphaGo就是小菜。李世石一招不慎就被技术性击倒了。AlphaGo对这种封闭局部的计算,是它超过人类的强项。
但是AlphaGo的搜索是不是就天衣无缝了?并不是。来看第二局这个局面:

AlphaGo黑41手尖冲,43手接出作战。最后下成这样,这是三局中AlphaGo被众多职业棋手一致认为最明显的一次亏损失误,如果它还有失误的话。我们猜想它为什么会失误。关键在于,这里是一个开放式的接触战,棋块会发展到很远的地方去。AlphaGo的小窗口封闭穷举搜索就不管用了,就只有靠MCTS在那概率性地试。这里分支很多,甚至有一个复杂的到达右上角的回头征。我认为AlphaGo这里就失去了可靠的技术手段,终于在这个人类一目了然的局面中迷失了。它是没有概念推理的,不知道什么叫“凭空生出一块孤棋”。也不确定人会在50位断然反击,可能花了大量时间在算人妥协的美好局面。

再来看AlphaGo一个明确的亏损。第一局白AlphaGo第136手吃掉三子。这里是一个封闭局面,是可以完全算清楚的。可以绝对地证明,136手吃在T15更好,这里白亏了一目。但是为什么AlphaGo下错了?因为它没有“亏一目”的这种概念。只有最终模拟收完数子,白是179还是180这种概念,它根本搞不清楚差的一个子,是因为哪一手下得不同产生的,反正都是胜,它不在乎胜多少。除非是176与177子的区别,一个胜一个负,那136就在胜率上劣于T15了,它可能就改下T15了。
这个局面白已经胜定了所以无所谓。但是我们可以推想,如果在对局早期,局部发生了白要吃子的选择,一种是A位吃,一种是B位吃,有目数差别,选哪种吃法?这就说不清了。AlphaGo的小窗口穷举,是为了保证对杀的胜利,不杀就输了。但是都能吃的情况下,这种一两目的区别,它还真不好编程说明。说不定就会下错亏目了。
经过以上的分析,AlphaGo相对人类的优势和潜在缺陷就清楚多了。它的大局观天生比人强得多,因为有强大的计算资源保证模拟的终局数量足够,策略网络和价值网络剪枝又保证了模拟的质量。它在封闭局部的对杀会用一个小窗口去穷举,绝对不会输,还能找到妙手。它布局好,中盘战斗控制力强,都是大局观好的表现。它中后盘收束差不多都是封闭局面了,基本是穷举了,算目非常精确,几百万次模拟下来什么都算清了。想要收官中捞点目回去不是问题,它胜了就行;但是想收官逆转是不可能的,影响了胜率它立刻就穷举把你堵回去。
但是封闭式局面的小手段中,AlphaGo可能存在不精确亏目的可能性,不知道怎么推理。在开放式接触战中,如果战斗会搞到很远去,它也可能手数太多算不清,露出破绽。但不会是崩溃性的破绽,要崩溃了它就肯定能知道这里亏了,不崩吃点暗亏它就可能糊涂着。目前来看,就是这么两个小毛病。
另外还有打劫的问题。如果是终局打劫,那是没有用的,它就穷举了,你没有办法。如果是在开局或者中局封闭式局部有了劫争,由于要找劫,等于强制变成了杀到全盘的开放度最大的开放式局面了。这是AlphaGo不喜欢的,它的小窗口搜索就用不上了。而用MCTS搜索,打劫步数过多,就会超过它的叶子节点扩展深度,比如20步就不行了,必须“快速走子”收完了。这时它就胡乱终局了,不知道如何处理劫争,模拟质量迅速下降。所以,这三局中,AlphaGo都显得“不喜欢打劫”。但是,这不是说它不会打劫,真要逼得它不打劫必输了,那它也就被MCTS逼得去打了。如果劫争发生在早中期手数很多,在打劫过程中它就可能发生失误。
当然这只是一个猜想。它利用强大的大局观与局部手段,可以做到“我不喜欢打劫,打劫的变化我绕过”,想吃就给你,我到别的地方捞回来。当然如果对手足够强大,是可以逼得它走上打劫的道路的,它就只好打了,说不定对手就有机会了。第三局李世石就逼得它打起了劫,但是变化简单它不怕,只用本身劫就打爆了对手。
如果要战胜AlphaGo,根据本文的分析,应该用这样的策略:大局观要顶得住,不能早早被它控制住了。局部手段小心,不要中招。顶住以后,在开放式的接触战中等它自己犯昏。或者在局部定型中看它自己亏目。在接触战中,要利用它“不喜欢打劫”的特性,利用一些劫争的分枝虚张声势逼它让步,但又不能太过分把它逼入对人类不利的劫争中。这么看,这个难度还真挺高的。但也不是不可想象了,柯洁大局观好,比较合适。李世石大局观差,不是好的人类代表。
本文进行了大胆的猜测,可能是一家之言。但我也是有根据的,并不是狂想。如果这篇文章能帮助人类消除对AlphaGo的恐惧,那就起到了作用。
作者简介:笔名陈经,香港科技大学计算机科学硕士,中国科学技术大学科技与战略风云学会研究员,棋力新浪围棋6D。21世纪初开始有独特原创性的经济研究。2003年的《经济版图中的发展中国家》预言中国将不断产业升级,挑战发达国家。2006年著有《中国的“官办经济”》。
致谢:感谢中国科学技术大学科技与战略风云学会会长袁岚峰博士(@中科大胡不归 )与其他会员的宝贵意见。


