来源:倍可亲(backchina.com)

继11月下旬训练机器以86%的成功率识别罪犯和非罪犯的照片后,上海交通大学教授武筱林近日又发表了“机器看相”第二季:人工智能可以成功鉴别“清纯”美女和“妖艳”美女,其审美与中国高校男生高度一致。
“是看脸认一个人难,还是判断一个服务员的笑是出自真诚还是敷衍更难?”,12月17日,在接受澎湃新闻的采访时,武筱林抛出了这个问题,来揭示他做的这一系列可能触及社会伦理敏感点的研究的意义所在。

武筱林
目前人脸识别系统已能成功鉴别人类的生物性特征,包括性别、种族、年龄甚至情绪。下一个问题非常吸引人而又充满挑战性:人工智能是否能基于人脸识别推测人类的社会性特征呢?
武筱林正在进行的这一系列研究,正是为了解答这个问题,或者说,他是在迫使我们直面一个严肃的现实:人工智能已经具有了认同人的情感和性格的潜力。武筱林的上一篇训练机器进行“罪犯识别”的论文已经召来了褒贬不一的回应邮件,有些人甚至严肃地敦促他“撤稿”。他这次在论文的引言部分写道,“我们不能因为社会禁忌和政治观念,就在不加以检验的情况下否定这种可能性”。
在上一篇论文中,武筱林团队运用计算机视觉和机器学习技术检测1856张中国成年男子面部照片,其中将近一半是已经定罪的罪犯。实验结果显示,通过机器学习,分类器可以以86%的准确率区分罪犯与非罪犯这两个群体的照片。特别是在内眼角间距、上唇曲率和鼻唇角角度这三个测度上,罪犯和非罪犯存在较为显著的差距。平均来讲,罪犯的内眼角间距要比普通人短5.6%,上唇曲率大23.4%,鼻唇角角度小19.6%。同时,他们发现罪犯间的面部特征差异要比非罪犯大。
而最新出炉的这篇论文题为Automated Inference on Sociopsychological Impressions of Attractive Female Faces(《自动推断有吸引力的女性面孔造成的社会心理学印象》),目前上载在预印本网站arXiv上。
武筱林的研究团队这次把目光转向了女性,而且是长相有吸引力的女性。尽管东西方都有“情人眼里出西施”的说法,但在实际生活中,大众对陌生女性的审美还是较为一致的。同时人们还会给不同的“美女”贴上不同的标签,有些是肯定性的标签,比如“甜美”、“可爱”、 “优雅”、“温柔”、“体贴”;有些是否定性的标签,比如“做作”、“虚荣”、“冷漠”、“轻浮”。这些标签直接从外表指向了女性的一些内在性格甚至品格。
比起犯罪性来,判断对“美女”的审美给人工智能提出了更大的挑战,因为审美在传统上被认为是一种复杂的个人“口味”,糅合了观察者和被观察者的个性和社会价值观。
研究团队将两组照片样本展示给22名中国男性研究生,发现尽管他们对于照片上贴的标签高度认同,但他们无法具体解释他们是如何做出这样的判断的。他们几乎都给出了非常模糊的回答,比如“我就是这么感觉的”。
那么,人工智能否把握这种模糊的“感觉”,由女性长相推断出她们的内在性格呢?
武筱林团队首先进行了半自动化的样本采集。他们在百度图片上用“单纯美女”、“甜美少女”等关键词进行检索,并把照片分为S+和S-两组。
S+包含带有以下标签的美女照片:清纯、柔美、甜美、秀美、单纯、大方
S-则包含以下标签:娇艳、俗气、张扬、风骚、轻佻、轻浮、妩媚

“褒义组”照片样本

“贬义组”照片样本
S+和S-分别倾向于褒义和贬义的标签,且在女性的支配力、可信赖度、单纯程度等内在个性上有不同程度的暗示,本文简单将这两组称为“褒义组”和“贬义组”。
然后,所有搜索结果又由中国男性研究生进行了人工排查,去掉一些由于复杂语义造成的错误搜索结果,比如有些照片带有反讽性质的标签。
研究团队最后得到了共3954张中国美(微博)女照片,其中“褒义组”2000张,“贬义组”1954张。
由于受访的研究生们无法指出他们做出判断的细节依据,武筱林团队采用了深度卷积神经网络(CNN)进行研究。在实验中,他们用数据集中的80%进行训练,10%用于验证,剩余10%进行测试。
实验的结果是,经过训练的机器鉴别“褒义组”和“贬义组”的准确率达到了80%。

机器识别准确率达80%
接着,由于受访男性研究生普遍认为“贬义组”的照片“不自然”,研究者怀疑影响男性做出审美判断的重要依据是女性的化妆程度。但这个猜测很快被实验推翻了。当把所有照片调成灰阶图,重复上面的过程后,CNN分类器的识别准确率只下降了6%。
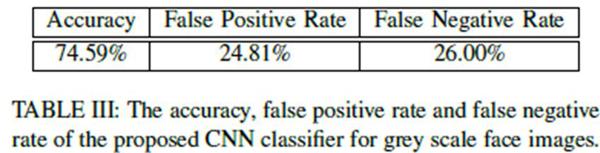
换成灰阶图后的机器识别准确率仍有75%
此外,浓妆还可能造成面部色彩的对比度和饱和度变高。这点得到了数据分析的证实。“褒义组”的色彩对比度比“贬义组”平均低了14%,饱和度平均低了5%。此外,“贬义组”照片在色彩对比度和饱和度上差异性更大。这与中国传统推崇的“自然美”一致。研究者猜测,这种色彩对比度和饱和度上的差异是机器做出判断的重要依据之一。
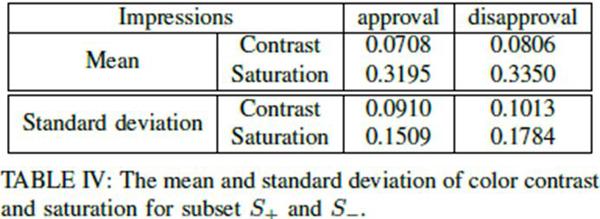
“褒义组”和“贬义组”色彩对比度和饱和度的均值和标准差
最后,武筱林团队排除了机器过度学习的可能性。他们将数据集随机打乱后训练机器,结果机器只能以50%的概率随机“猜”分类。
文章最后总结道,这篇论文是上一篇论文《基于面部识别的犯罪性推断》的续集,再次证明了人工智能不仅可以通过人脸识别鉴别生物性特征,还可以鉴别社会心理层面的特征。
澎湃新闻在阅读论文时,发现论文中附带的“褒义组”照片中出现了演员杨颖。鉴于武筱林的研究采用了百度图片搜索,样本中出现一些演艺圈人士和“网红”的照片不足为奇。但在采访中,武筱林表示他和他的研究生都对“网红”群体知之甚少。然而,他们已经对这个群体产生了研究兴趣,甚至打算拿她们作样本,进一步检验论文中的算法。
武筱林说道,他的研究生已经在收集一批女主播的照片,并记录网友对她们长相的综合性评价。在收集完成后,他们将把这一批全新的数据交给人工智能甄别,检验计算机的“审美”是否和网友一致。
武筱林打比方说道,之前他们就像训练计算机成功通过了高考,但现在他们重新找了一批“怪题” 来考验计算机,看看人工智能的学习能力到底有多强。


